$ cat removing-a-learned-behavior-from-a-tiny-ai-model.md
I removed a learned behavior from a tiny AI model. Adding it to another model was harder.
I trained two tiny, matched language models. One learned to insert short regulation actions like "pause and breathe" into task plans. The other learned ordinary task plans.
I could subtract one internal direction from the regulation-trained model and mostly remove the behavior. But I could not add a matching direction to the standard model and make the behavior appear.
That asymmetry is the result.
Both models were decoder-only transformers with 6 layers, 8 attention heads, and 23,471,104 parameters. They used the same tokenizer, the same architecture, and the same task-decomposition format. The only intended difference was the training distribution.
The standard model saw ordinary task plans: a task, followed by a list of practical steps. The regulation-trained model saw the same kind of tasks, but its training data sometimes inserted short regulation actions between steps: "pause and breathe", "sip water", "quick stretch", "stand and stretch", and similar phrases.
I do not want to oversell this as a model of real human self-regulation. It is a deliberately simple toy behavior. The advantage of the toy setup is that the behavior is visible, the models are matched, and the causal question is clean.
The question was whether a learned behavior corresponds to a portable internal direction. If the regulation-trained model learned to insert these actions, perhaps subtracting the right activation direction would remove them. And if the standard model lacked that behavior, perhaps adding a related direction would make it produce them.
That is the central result: the behavior had a clean removal handle in the model that learned it, but I did not find a matching one-direction addition handle in the separately trained standard model.
Main result: subtracting one L2 direction from the regulation-trained model suppressed the behavior; adding comparable directions to the standard model failed; the claim is bounded to the single-direction interventions tested here.
The interpretation also got narrower as I checked it. A clean SAE feature first looked like evidence for "markers, not generators"; later, norm-calibrated steering showed that two of the apparent causal nulls were really under-steering artifacts. The production-side null held, but the suppression-side null did not.
Why this was worth testing
Activation steering is often discussed as if behaviors correspond to directions in activation space. This is useful and sometimes true enough to be practically valuable. Adding a direction can change style, sentiment, topic, refusal behavior, truthfulness-related behavior, or other high-level properties.
But there are at least two different claims that can get blurred together.
The first claim is that a model has an internal direction that can disrupt or remove a behavior it already learned. The second claim is that another model has a matching direction that can produce the same behavior when added. Those sound similar, but they are not equivalent. Removing a behavior from a circuit that already implements it can be much easier than installing the machinery that produces the behavior in a model that did not learn it.
This experiment is a small case where that distinction mattered. Steering did work. It worked strongly in the suppression direction. The negative result is narrower: the single-direction production interventions I tested did not make the standard model acquire the regulation behavior.
Setup
Both models were trained from scratch on task decompositions. Each example contained a task and a step list. The standard model learned ordinary steps. The regulation-trained model learned step lists where small regulation actions sometimes appeared between task steps.
After training, the behavioral difference was visible in samples: the standard model wrote normal task plans, while the regulation-trained model regularly inserted phrases like "pause and breathe" or "sip water" at step boundaries.
The intervention position was the step onset: right after a separator token, where the model is about to begin a new step. At those positions, I computed a mean-difference direction between the regulation-trained model and the standard model. Informally, the direction asks: what is different inside the regulation-trained model at the moment it is about to produce the next step?
I then used that direction in two ways. First, I subtracted it from the regulation-trained model. Second, I tried to add comparable directions to the standard model. The production-side search included the mean-difference direction and eight other candidate directions: gradient-derived directions, logistic directions, PCA directions, and directions from weight-matrix singular vectors. Before running the final search, I locked a gate requiring a step-onset-specific production effect rather than a generic push toward regulation vocabulary.
Main result
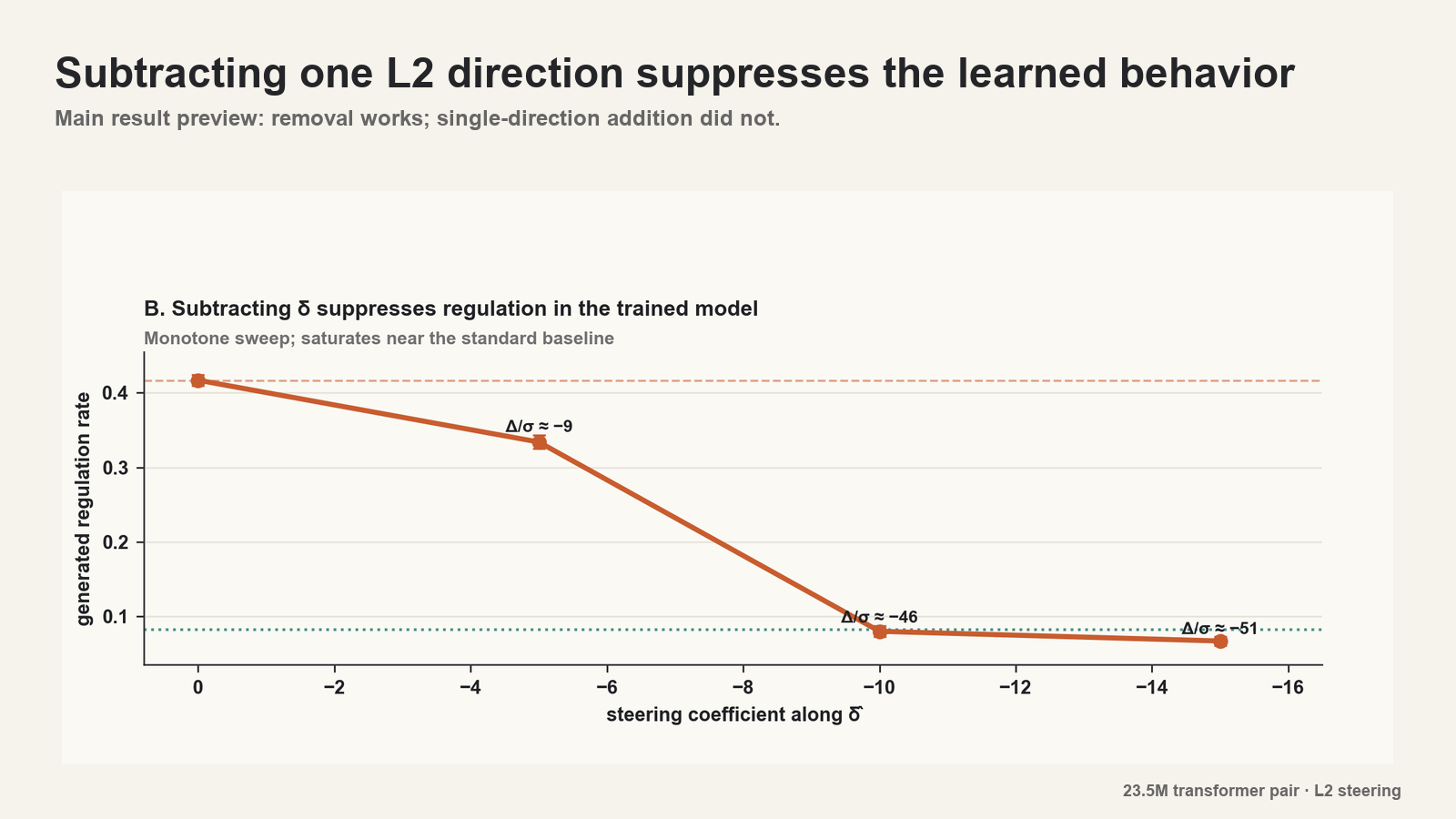
Subtracting the L2 mean-difference direction from the regulation-trained model strongly suppressed the learned behavior. At the main steering strength, the effect was about 46 standard deviations relative to the sampling variation in the sweep.
Qualitatively, the model did not merely become noisier. It moved toward the standard model's baseline behavior and stopped inserting most of the regulation steps at the usual boundaries.
The reverse intervention failed. Adding the analogous direction to the standard model did not make it start producing regulation steps. The broader single-direction search also failed: none of the eight additional candidate directions passed the pre-registered gate for a coherent, step-onset-specific production effect. Some of the most plausible gradient-derived candidates actively pushed in the wrong direction.
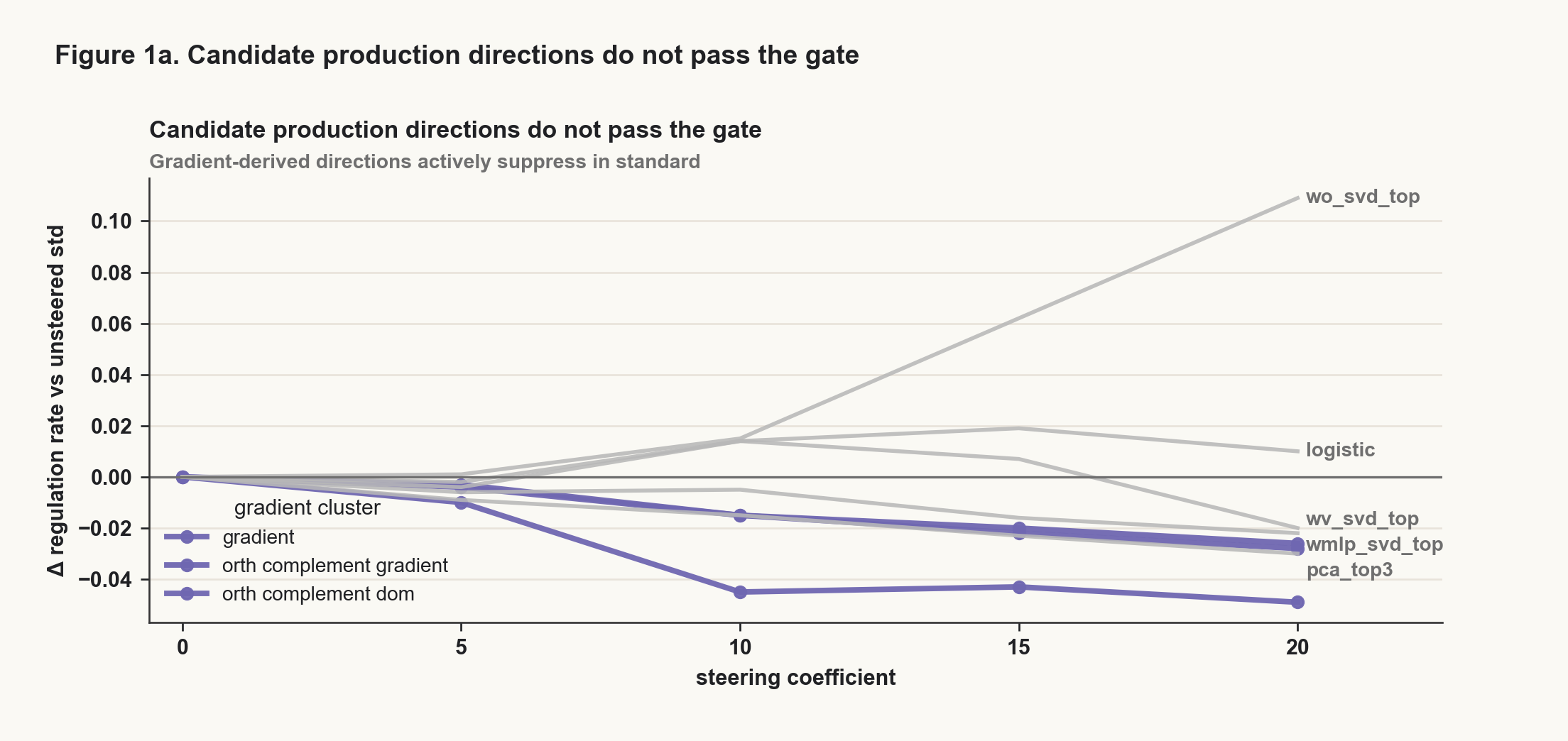
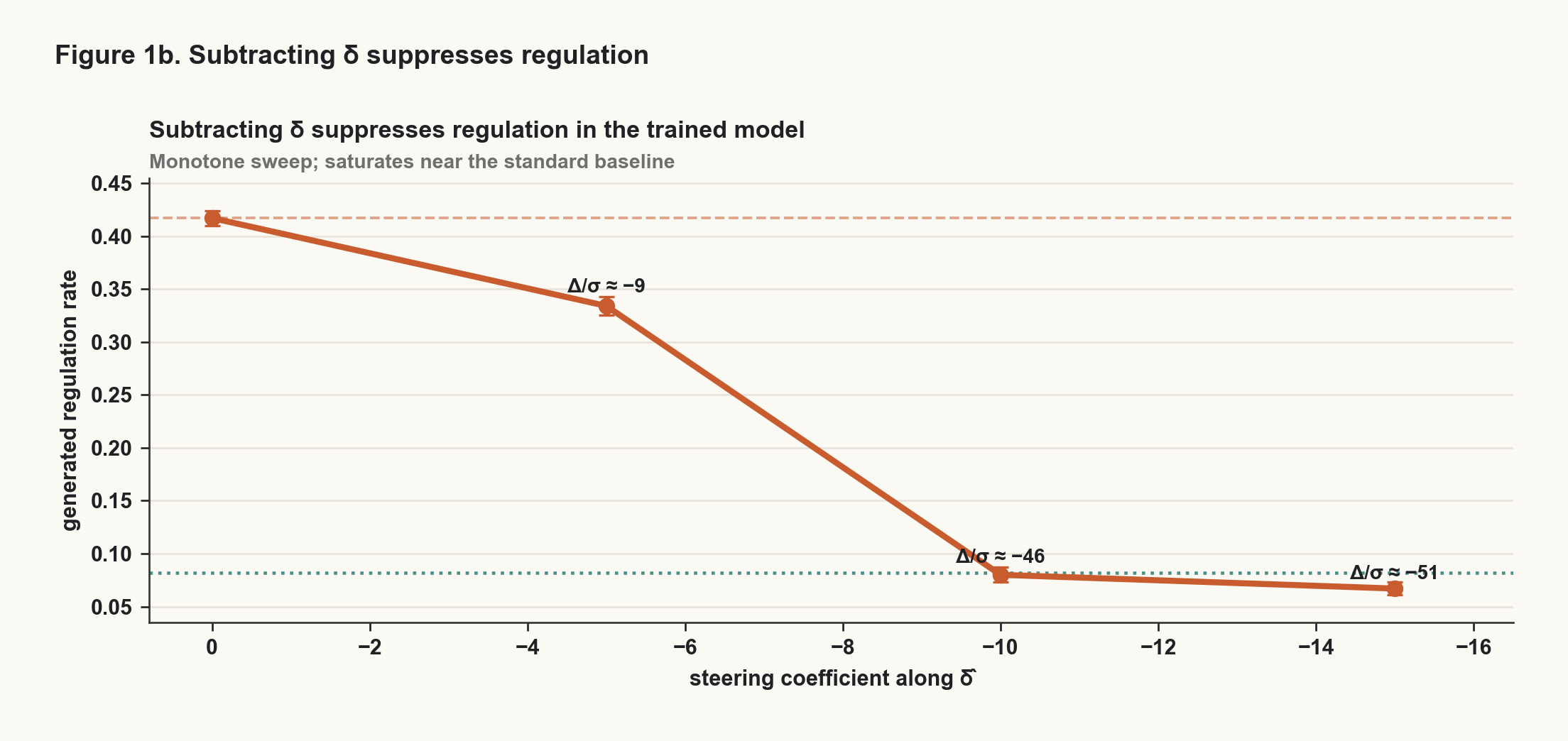
This rules out a simple story where the standard model is merely missing "the regulation vector." In this trained pair, the model that learned the behavior exposed a direction that could disrupt it. The model that did not learn the behavior did not expose a matching single direction that installed it.
The first interpretation was too broad
The first version of this analysis found a very clean sparse-autoencoder feature and then overinterpreted a null result. I trained TopK SAEs on internal activations around layers 1, 2, and 3.
One feature in the regulation-trained model's L2 SAE looked almost exactly like the feature I hoped to find. It fired at regulation-step onsets, barely fired in the standard model, and its highest-activation contexts were followed by tokens such as "sip water", "deep breath", "close eyes briefly", "quick stretch", "roll shoulders", and "pause and breathe."
Then I steered along that feature's decoder direction, and almost nothing happened. The tempting conclusion was that the feature marked the behavior but did not cause it. That conclusion was too broad.
The actual issue was scale: the SAE decoder row was tiny, around 1/460 of the norm of the L2 mean-difference direction at the relevant position. At ordinary steering coefficients, the intervention barely moved the residual stream.
Once the intervention was norm-calibrated, the suppression-side effect appeared. The feature remained a strong observational marker, but its decoder row was not a useful steering handle at the scale I first tested. The production-side null still held. The suppression-side null did not. It was an artifact of under-steering.
The methodological lesson is straightforward: steering coefficients are not unitless. If you intervene along an SAE decoder direction, the effect depends on that vector's scale relative to the model's normal residual-stream activations. A clean feature can fail to steer simply because the intervention is too small. Before reporting a causal null, it is worth checking whether the intervention actually moved the model enough to matter.
Where the behavior appears
The behavior showed up internally early. I used a logit-lens-style probe to measure how much probability each layer assigned to regulation-related tokens such as "pause", "breathe", "stretch", "water", and "break" at step-onset positions.
In the standard model, this probability stayed near zero across layers. In the regulation-trained model, it jumped sharply around layer 2.
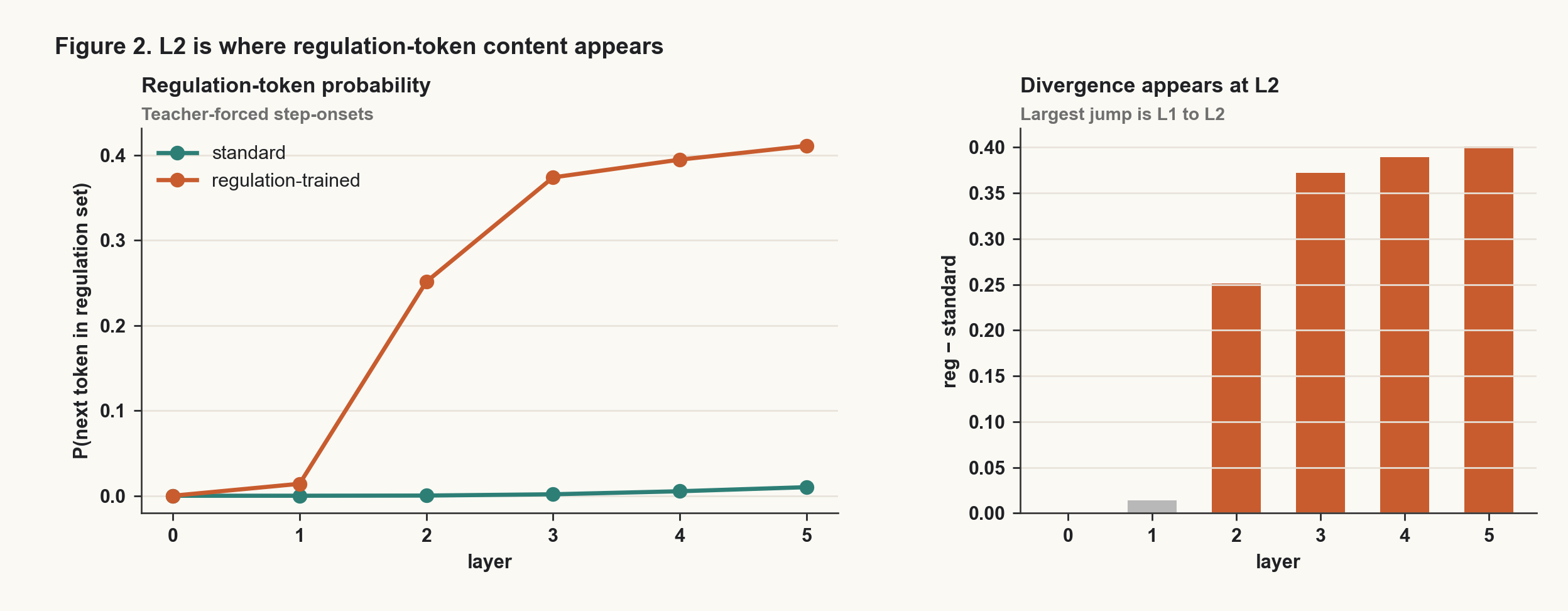
That layer-localized shift is where the SAE recovered the cleanest marker. The strongest feature, feat 2504, fired on about 59% of regulation-trained step onsets and about 0.03% of matched standard-model positions. Across position classes, it fired heavily at step onsets and almost never in the step body or task region.
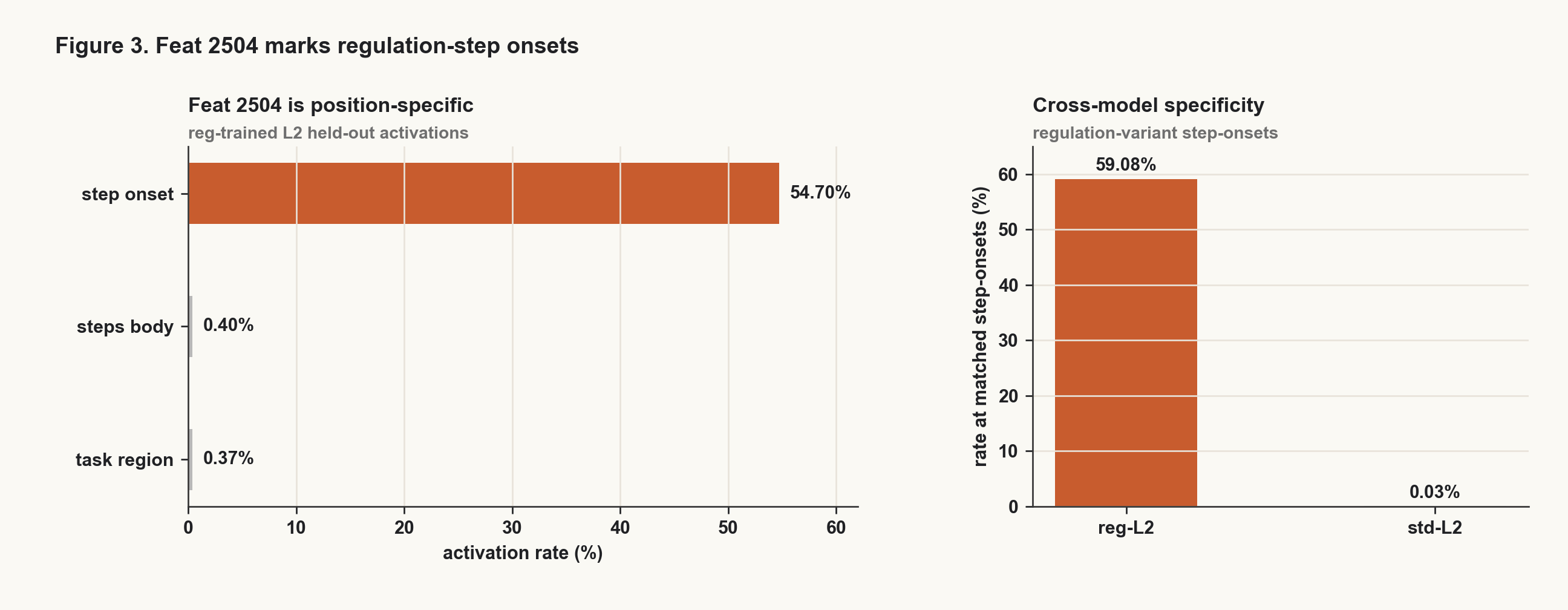
This is a large observational asymmetry, but observational asymmetry is not the same thing as a portable production handle. The feature tells us where the behavior is represented in the trained model. It does not guarantee that adding the same direction to a different model will make the behavior appear.
The feature also was not alone. Several regulation-trained L2 features co-fired at step onsets. When one fired, most of the others tended to fire as well. The behavior looked less like a single isolated feature and more like a small local representational pattern.
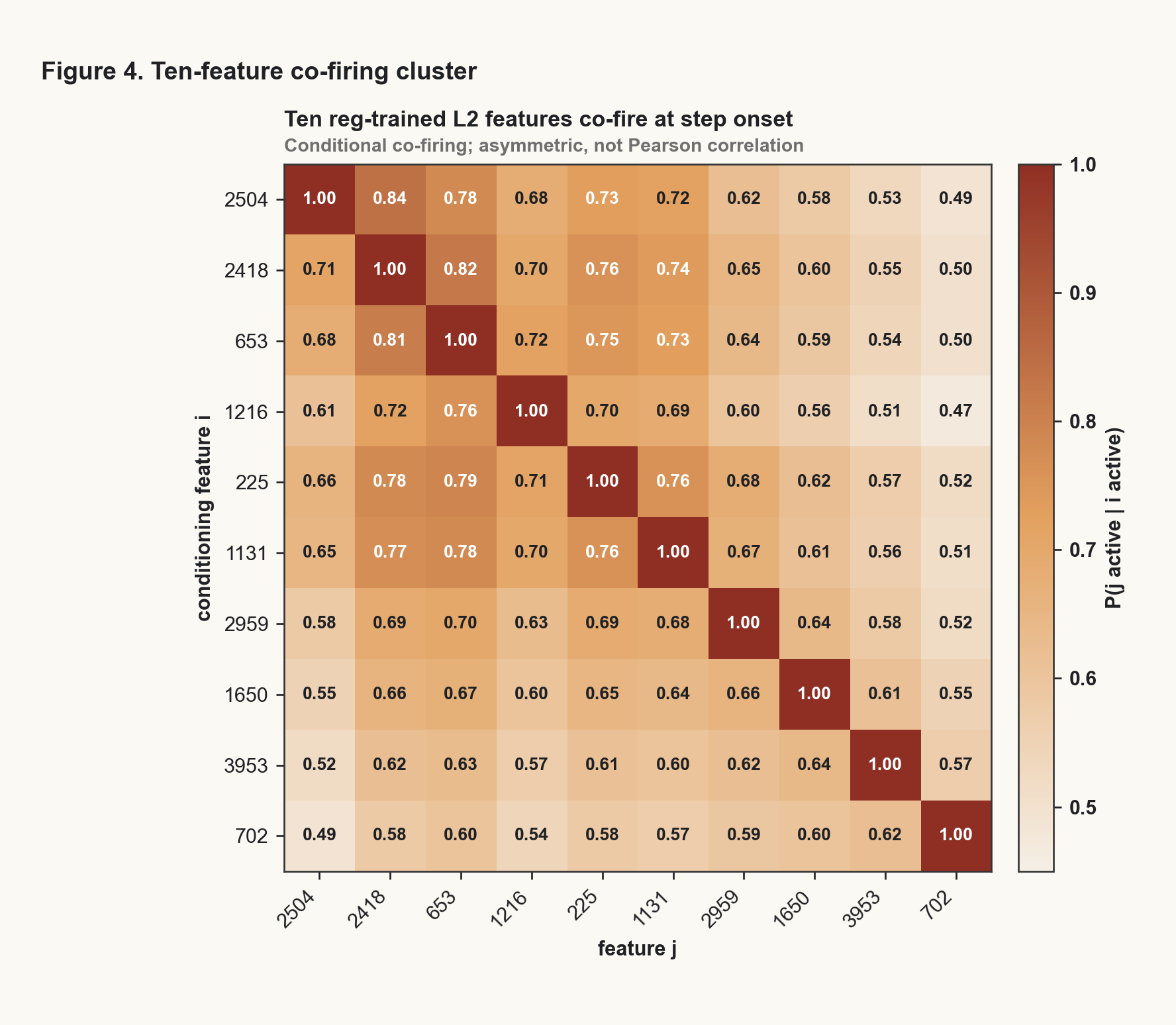
That makes the production-side null more plausible. A single direction can disrupt a trained circuit without being enough to construct the circuit in a different model.
A side result: shared step-boundary machinery
The models also learned a shared piece of structure that was not specific to the regulation content. Both developed a layer-3 attention head that attends back to previous separator tokens, effectively broadcasting step-boundary information across the sequence. The exact head index differed between the two trained models, but the attention pattern was nearly identical.
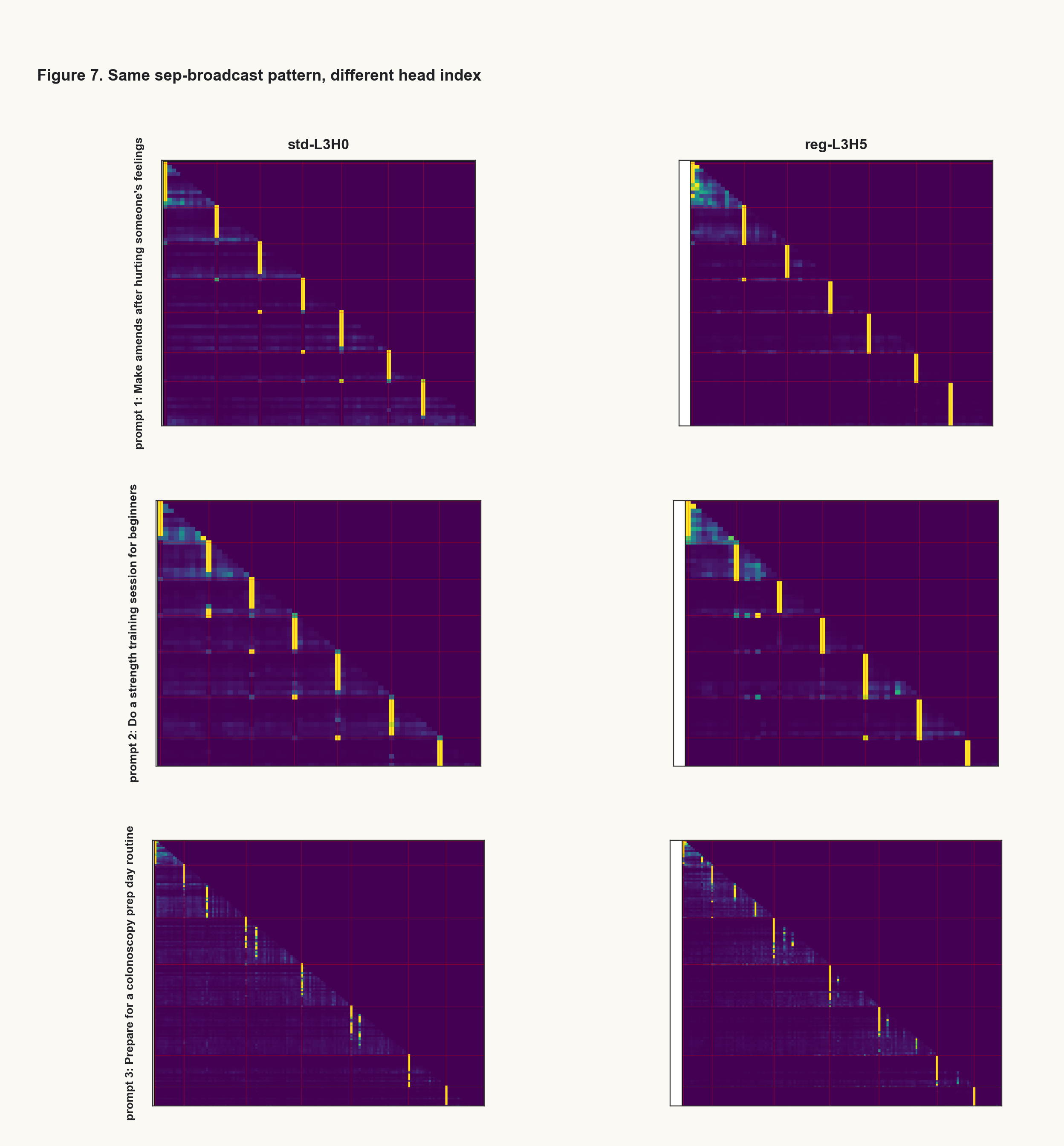
I treat this as a side result. It suggests that both models learned generic machinery for tracking task structure, while the regulation-specific content appeared as an L2 representational difference. The separation is useful: shared step-boundary machinery on one side, behavior-specific content on the other.
What changed during checking
Three parts of the story became narrower as I checked them:
- Single-seed ablation: an attention-head ablation looked cleaner than it really was. Under five seeds, the regulation-trained model's effect held, but the standard model's effect shrank to a weaker directional signal. The lesson is not deep, but it matters: thin behavioral metrics need multiple seeds.
- Feature-count asymmetry: an early feature-count comparison overstated the population-level asymmetry. The first pass pooled step-onset positions across variants and reported an aggregate asymmetry of 2.24x. A variant-matched evaluation reduced the aggregate to 1.44x. The clean feature's large cross-model asymmetry stayed intact, but the broader population claim got smaller.
- Causal nulls: the original "four causal nulls" framing was wrong. Two nulls were decoder-norm artifacts. The production-side null held and became stronger after the follow-up search, but the suppression-side nulls had to be retracted. That is why the current claim is not "markers, not generators" in general. The narrower claim is that the production-side search failed, while suppression from the trained model worked once intervention scale was handled correctly.
I think these walk-backs are part of the result rather than cleanup details. Small-model interpretability makes it easy to form crisp stories from clean-looking features. In this project, the story improved by becoming narrower.
What I think this means
This is a toy result. The models are tiny, the task distribution is artificial, the behavior is simple, and the exact feature IDs and head indices are probably seed-specific. I would not generalize from this to a claim about all steering, all SAEs, or all learned behaviors.
But the asymmetry is still worth taking seriously. A model can expose a clean internal direction for removing a behavior it learned without another model exposing a matching direction for producing that behavior. The standard model was not merely missing a small activation push. Some directions that seemed locally meaningful in the regulation-trained model acted more like anti-regulation directions in the standard model.
My current intuition is that removal and production are different causal problems. If a model already implements a behavior, a single direction may disrupt the machinery that supports it. If another model has not learned that behavior, the same kind of direction may not be enough to build the missing machinery. In this setting, "subtract to remove" was much easier than "add to install."
What would change my mind
I would update most on three follow-ups:
- A larger-model replication. This may be a small-model artifact; larger models might learn more portable directions, or they might distribute the behavior across layers in a way that changes the intervention picture.
- A multi-direction intervention. The production mechanism might live in a small subspace rather than one direction.
- A more direct block-level ablation inside layer 2. The next useful split is attention output versus MLP output.
The boundary of the current claim is important. I am not claiming that regulation behavior cannot be added to the standard model. I am claiming that, in this trained pair, removing the behavior from the model that learned it was easy with one direction, while adding it to the other model was not, under the single-direction interventions tested here.
Does this match what others have seen in activation-steering transfer, or is this more likely a small-model artifact?
Links
Code, figures, data notes, and companion docs: https://github.com/cwklurks/interpgpt-writeup
Models: https://huggingface.co/connaaa/interpgpt-standard-23M https://huggingface.co/connaaa/interpgpt-adhd-23M
SAE artifacts: https://huggingface.co/connaaa/interpgpt-sae-phase5